
How (Multi-headed) Self Attention Blocks Work
What are multi-headed self attention blocks and how do they fit into transformers.
Transformer blocks
After tokenization, we take the input embeddings and passing them through a series of transformer blocks. The output is a set of modified embeddings corresponding to the input tokens that contain information about the context. The output of the transformer block is then added to the input embedding and passed through the next transformer block.
In each transformer block, the input embeddings are passed through a series of layers:
- layer normalization
- multi headed self attention block
- layer normalization
- feed forward layer (multi layer perceptron)
Multi headed self attention block
The self attention block consists of a query, key, and value matrix. The values in these matrices are learned during training. The query matrix is multiplied with each of the embeddings. The result is a set of query vectors for each of the input tokens. The key matrix is also multiplied with each of the embeddings. The result is a set of key vectors for each of the input tokens.
A dot product is computed between each query vector and each key vector. This results in a grid called an attention pattern. The size of this grid is the size of the block which is the number of tokens in the input sequence (i.e. context size). This is because in a given input sequence, we can generate context size number of examples where each example is the current token and the list of all previous tokens. If the dot product is large, the two vectors are similar and the embedding referred to by the query vector is highly relevant to the embedding referred to by the key vector. The key token attends to the query token.
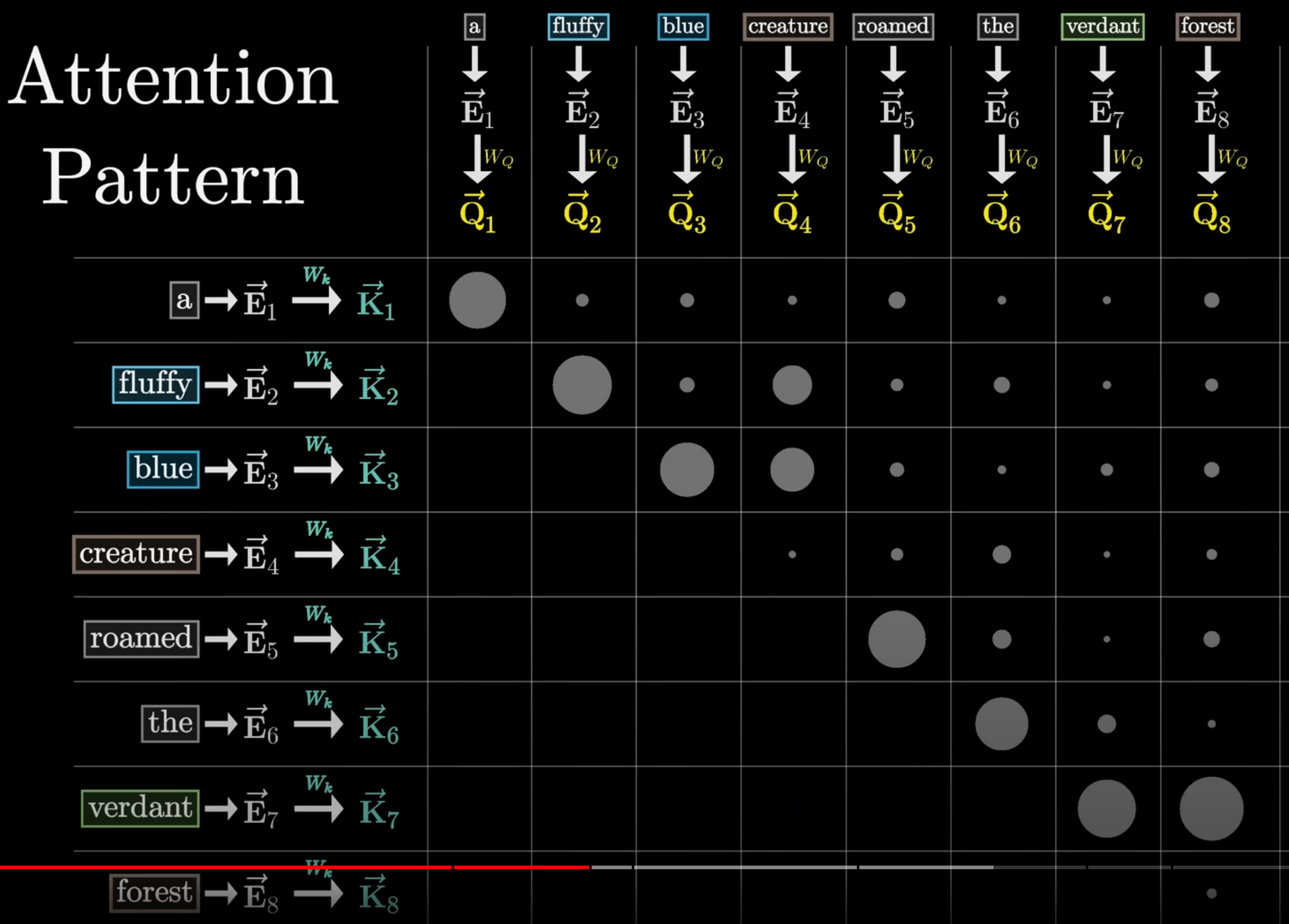
The dot product values in each row are then passed through a softmax function to have each column’s values sum to one. Note that since we only care about previous tokens affecting the current token, we zero out the values in the attention pattern that correspond to future tokens by setting those values to negative infinity and letting the softmax function push all those values to zero.
Now we multiply the value matrix by each of the previous token’s embeddings in the context to generate a set of value vectors for each input embedding. The value vectors are “weighted” by the dot product values in the attention pattern. Then they are summed up to produce a single output vector that can be thought of as the embedding change to be added to the query embedding to refine the query embedding to match the context more.
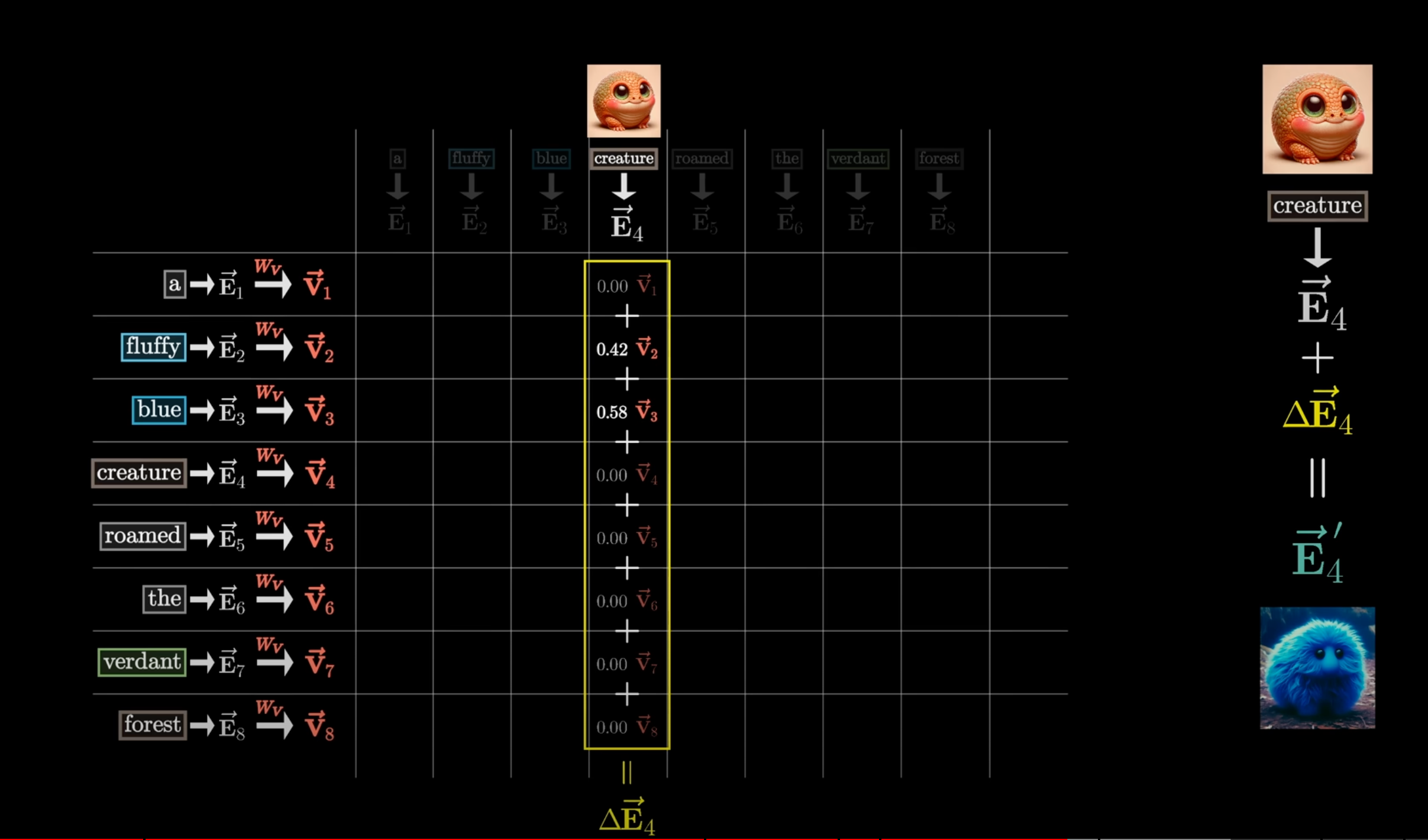
This is how the attention block produces a set of output changes that refine the input embeddings to match the context more.
A full attention block has multi headed attention blocks. Each attention block is what is described above with its own Key/Query/Value matrices. Each of the attention blocks in the multi headed attention blocks produces a change to be applied to the embedding of a particular token. These changes are vectors that are added to the original embedding. Conceptually this can be thought of as updating the context of a specific token based on many different